爬虫实战-获取某租房网站的房源信息
Github代码地址
帮助朋友编一个爬虫来获取信息建立房价预测的数据集,顺便回忆一下之前自学的爬虫。首先确定好要使用的几个库。
- requests库模拟请求
- BeautifulSoup库处理数据
- json库序列化接口数据
- traceback库打印请求信息
- 保存数据的库一开始本来是用xlwt的,但是写完发现保存的数据无法被pandas读取(编码问题),于是采用csv库
手搓爬虫开始
直接用request发请求的话必然是会被阻拦的,尝试了下返回403,果然被拦截了。那么这时候就要把爬虫伪装一下。添加头部信息:1
2
3
| headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76"
}
|
从首页可以看出我们需要的数据在列表那个部分,思路就能比较清晰了:首先要获取到每页列出的所有房屋id,在进入到这个房屋的详情页去获取数据(虽然也能从首页直接获取,但是数据太少,比如周围的医疗设施、交通情况就要去详情页)。由于这种网站这部分的数据一般是用动态渲染完成的,所以不能直接爬这个网站,有两个办法可以获取。
- 使用selenium库自动化模拟打开这个页面获取房屋列表,再用爬虫去爬房屋详情网站。
- 优点
- 不用担心数据是加密的。
- 能够完全加载页面,基本需要的数据都有。
- 缺点
- 慢,要爬好几页的话效率巨低。
- 找到请求接口,直接用爬虫去请求这个接口来获取数据。
- 优点
- 快,效率高,编写方便。
- 缺点
- 要从请求列表中的茫茫请求量中找到这个接口,看脸。
- 数据可能被加密过
一开始我是选择采用了selenium库,编写完后发现效率实在是低,一个页面的二十条数据要二十秒才能完成,干脆采用了第二种。那就得先找接口。
按F12打开控制台,点击网络,刷新网页
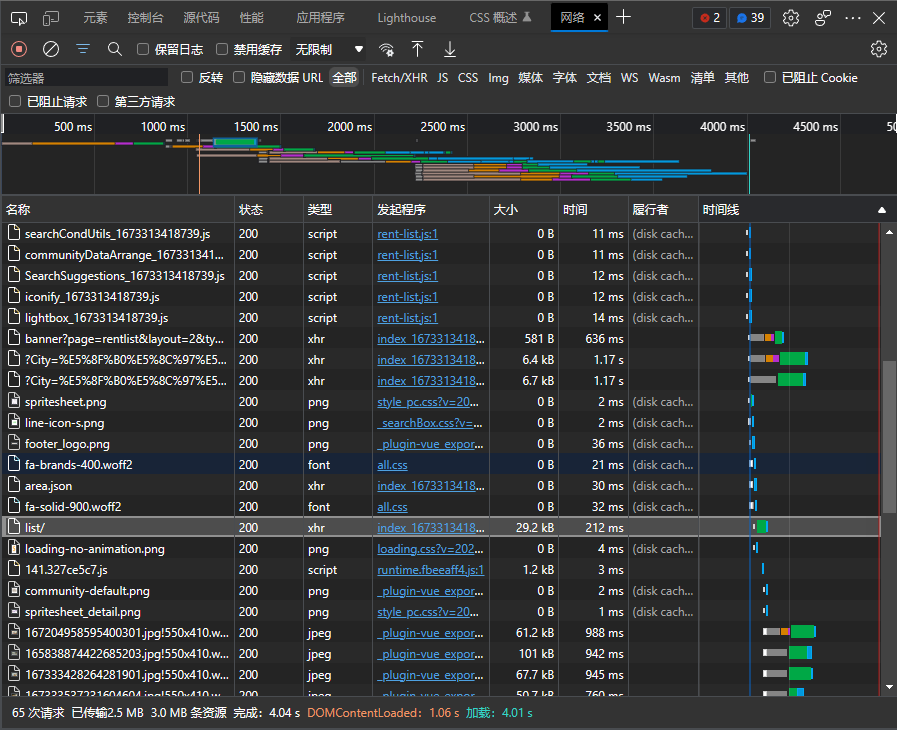
其中这个list请求很可疑,点进去看看
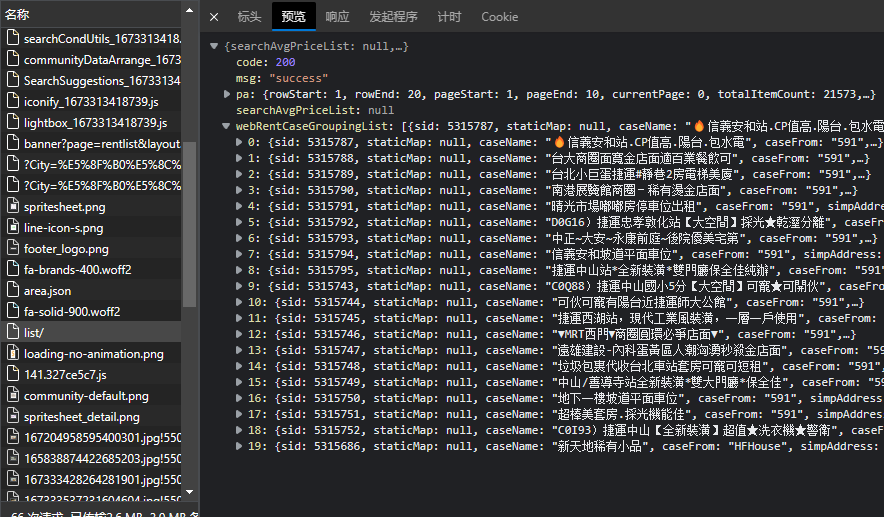
非常轻松的就找到了。点击标头复制请求地址https://rent.houseprice.tw/ws/list/,不过先别急,既然有分页,那肯定还需要找一下分页的参数在哪,点击第二页,发现请求地址是https://rent.houseprice.tw/ws/list/?p=2,那答案就很明显了。
编写通用请求函数
1
2
3
4
5
6
7
8
9
|
def requests_houses(url):
try:
response = requests.get(url=url, headers=headers)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
|
定义执行函数
1
2
3
4
| def main(page):
housesPageInfo = json.loads(requests_houses("https://rent.houseprice.tw/ws/list/?p=" + str(page)))
housesList = housesPageInfo.get('webRentCaseGroupingList')
|
此时,houseList就是包含了这个页面所有房屋信息的数组,只需要遍历取出sid就可以了。再分析一下房屋详情页的网址。我们随便点进去一个出租的房屋,发现网址是https://rent.houseprice.tw/house/5315687。那接下来怎么写就很清楚了,只需要拼接前缀与sid即可。
1
2
3
4
5
6
7
8
| def main(page):
housesPageInfo = json.loads(requests_houses("https://rent.houseprice.tw/ws/list/?p=" + str(page)))
housesList = housesPageInfo.get('webRentCaseGroupingList')
for item in housesList:
item_url = 'https://rent.houseprice.tw/ws/detail/'+ str(item.get('sid'))
print('正在爬取' + item_url + '的数据...')
|
现在开始分析详情页的数据,还是一样,找接口,过程就不说了,全凭经验和直觉。直接放图分析数据。
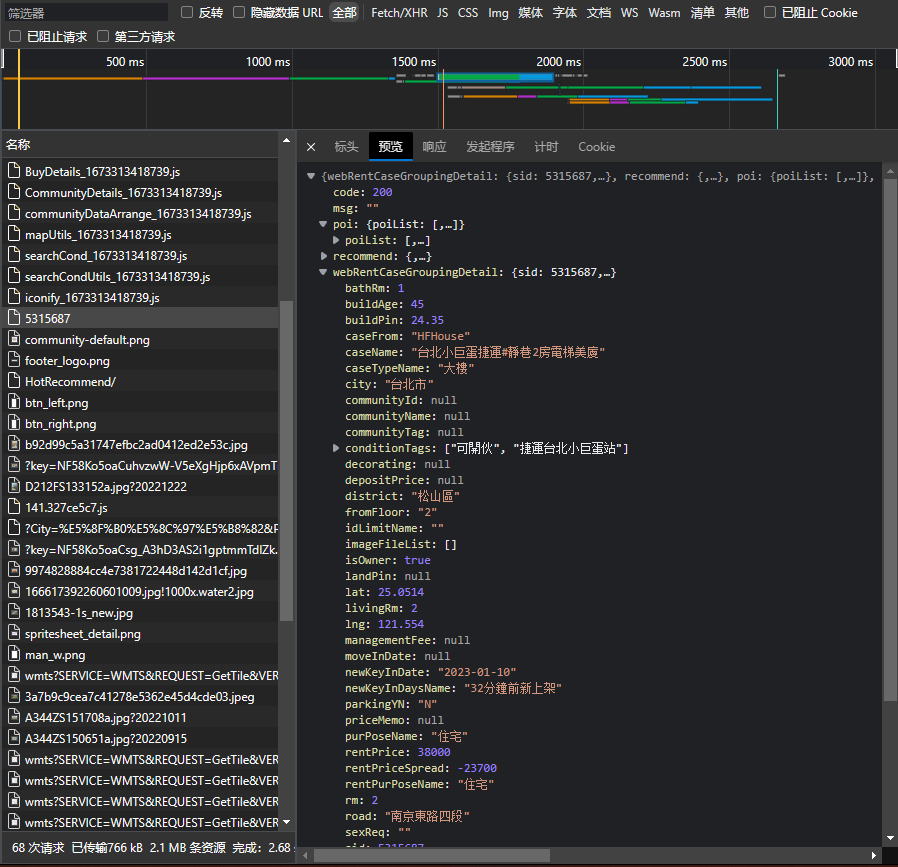
很明显这个webRentCaseGroupingDetail里的数据就是我们要的基本信息,点开poiList发现是生活地图里的内容,是周边所有医疗点、商城、交通的信息。
接下来就是拿这些数据塞到csv里了,直接放全部代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
| import requests
from bs4 import BeautifulSoup
import json
import traceback
import csv
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76"
}
csv_obj = open('rentData.csv','w',encoding='utf-8', newline='')
csv.writer(csv_obj).writerow(['房屋编号','室','厅','卫','起始所在楼层','所跨楼层','总楼层','租金/月','面积/坪','管理费/月','周边学校','周边交通','周边医疗','购物中心','嫌惡設施'])
n = 1
success = 0
fail = 0
def requests_houses(url):
try:
response = requests.get(url=url, headers=headers)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
def main(page):
housesPageInfo = json.loads(requests_houses("https://rent.houseprice.tw/ws/list/?p=" + str(page)))
housesList = housesPageInfo.get('webRentCaseGroupingList')
for item in housesList:
item_url = 'https://rent.houseprice.tw/ws/detail/'+ str(item.get('sid'))
print('正在爬取' + item_url + '的数据...')
try:
data = json.loads(requests_houses(item_url))
item_roomId = data.get('webRentCaseGroupingDetail').get('sid')
item_room = data.get('webRentCaseGroupingDetail').get('rm')
if item_room == None or item_room == '' :
item_room = 0
item_livingRm = data.get('webRentCaseGroupingDetail').get('livingRm')
if item_livingRm == None or item_livingRm == '' :
item_livingRm = 0
item_bathRm = data.get('webRentCaseGroupingDetail').get('bathRm')
if item_bathRm == None or item_bathRm == '' :
item_bathRm = 0
item_beginFloor = data.get('webRentCaseGroupingDetail').get('fromFloor')
if item_beginFloor == '--' or item_beginFloor == '' or item_beginFloor == None:
item_beginFloor = 0
item_floor = 0
else:
item_floor = int(data.get('webRentCaseGroupingDetail').get('toFloor')) - int(data.get('webRentCaseGroupingDetail').get('fromFloor')) + 1
item_upFloor = data.get('webRentCaseGroupingDetail').get('upFloor')
item_price = data.get('webRentCaseGroupingDetail').get('rentPrice')
item_buildPin = data.get('webRentCaseGroupingDetail').get('buildPin')
item_managementFee = str(data.get('webRentCaseGroupingDetail').get('managementFee'))
if item_managementFee == '無' or item_managementFee == None or item_managementFee == '':
item_managementFee = 0
else:
item_managementFee = int(item_managementFee[:-3].replace(',',''))
item_poiList = data.get('poi').get('poiList')
transport = 0
school = 0
medic = 0
shop = 0
bad = 0
for i in item_poiList:
if i.get('categoryType') == 2:
school = school + 1
elif i.get('categoryType') == 3:
medic = medic + 1
elif i.get('categoryType') == 4:
shop = shop + 1
elif i.get('categoryType') == 5:
bad = bad + 1
elif i.get('categoryType') == 1:
transport = transport + 1
global n
csv.writer(csv_obj).writerow([item_roomId,item_room,item_livingRm,item_bathRm,item_beginFloor,item_floor,item_upFloor,item_price,item_buildPin,item_managementFee,school,transport,medic,shop,bad])
n = n + 1
except Exception as e:
print(item_url + '数据处理失败:')
traceback.print_exc()
global fail
fail = fail + 1
else:
print(item_url + '数据处理成功')
global success
success = success + 1
if __name__ == '__main__':
for i in range(1, 2):
main(i)
print("爬虫执行完毕,成功" + str(success) + '条,失败' + str(fail) + '条')
csv_obj.close()
|
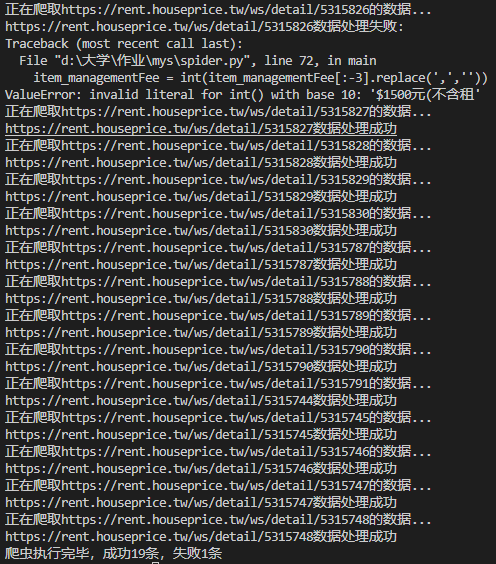
运行效果如下。因为湾湾程序员似乎没有统一空值返回的数据,有些返回空有些返回Null有些返回’–’,有些数据的返回也不理想,干脆直接跳过,所以做了异常处理。